Master 2, Bases de données avancées, année 2021
Cours 1. Rappel sur les bases de données relationnelles
Un système de base de données relationnelles (SGDBr) stocke les données dans des tables dont la structure est spécifiée par un schema relationnel. Les données sont mises à jour et interrogées via le langage déclaratif SQL.
L’objectif du système est de permettre un accès concurrent aux données en lecture et en écriture de manière homogène, efficace et durable. Il est très adapté pour représenter des données structurées qui évoluent de taille moyenne et réaliser des extractions ponctuelles.
Efficacité
L’efficacité d’un SGBDr repose principalement sur l’optimiseur de requêtes. Ce dernier va transformer une requête SQL (déclarative) en une suite d’algorithmes tirant parti de l’information disponible dans la base (statistiques, indexs).
Homogénéité
Lorsqu’un utilisateur consulte une base de données, un autre utilisateur peut la modifier simultanément, ce qui peut entraîner des comportements mal définis. Pour éviter ce type de problème, chaque transaction est isolée des autres via le Multiversion concurrency control. Ce dernier fournit une vue temporisée persistante sur l’état de la base de données pour chaque transaction ouverte.
Le MVCC de PostgreSQL s’appuie fortement sur le plan physique des tables. Chaque ligne de chaque table possède plusieurs champs représentant la transaction qui a inséré la ligne, la transaction qui l’a rendue obsolète ainsi qu’un pointeur vers la nouvelle ligne si cette dernière existe. Chaque transaction peut ainsi déterminer en fonction de ces informations si une ligne donnée est vivante ou morte pour elle. Une conséquence directe c’est qu’aucune ligne n’est jamais réellement supprimée lors des opérations normales des bases de données. Afin de supprimer les lignes, il est nécessaire de nettoyer la table à intervalles réguliers, notamment pour les bases de données avec beaucoup de mises à jour, via l’opération de vacuum.
Oracle gère ce type de problème différemment en modifiant la ligne en place et en insérant l’ancienne ligne dans un segment mémoire dédié à défaire les modifications les plus récentes, avec des mécanismes de recyclage de cet espace mémoire pour les modifications très vieilles.
Durabilité
Un SGBDr, pour être efficace, doit tirer parti des différents niveaux de cache afin d’accélérer certaines requêtes. Il n’est pas rare qu’une base de données puisse tenir complètement dans la RAM de la machine et il est donc très tentant d’utiliser l’accès rapide de la RAM afin d’améliorer grandement les performances du SGBDr. Cependant, en cas de panne machine (panne de courant par exemple), la RAM sera effacée et les morceaux de la base de données présents uniquement en RAM seront perdus. Les SGBDr doivent donc stocker sur disque les données de manière à garantir aucune perte en évitant que ce stockage impacte trop les performances du système.
Un mécanisme classique pour garantir la durabilité et la combinaison d’un Write-Ahead log en plus de processus dédiés afin de committer sur disque à intervalles réguliers.
Résumé
Un SGBDr offre des garanties ACID
- Atomicité
- Cohérence
- Isolation
- Durabilité
Ces propriétés sont importantes pour garantir que le système se comportera comme prévu. Néanmoins, certaines garanties sont trop coûteuses et uniquement partiellement satisfaites. Par exemple l’isolation des transactions peut être ajustée afin d’éviter que trop de transactions ne soient rejetées.
Les schémas relationnels
Un schéma relationnel comporte l’information de comment les données sont stockées dans différentes tables et de comment les différents champs sont liés entre eux.
Il comporte également:
- des ensembles de contraintes que la base de données doit respecter
- des vues (possiblement matérialisées)
- des triggers qui permettent de maintenir les contraintes et de simplifier l’interaction avec la base de données.
- des fonctions embarquées qui peuvent être exécutées dans les triggers mais aussi pour transformer/analyser les données.
Quand la base de donnée est dans un certain état, il peut être difficile de faire évoluer le schéma sans que celui-ci ne déclenche une erreur. Ajouter des champs par exemple est relativement simple, mais en fusionner peut entraîner de nombreuses erreurs et nécessite des traitements dédiés et souvent d’écrire des programmes pour nettoyer la base de données.
Il n’est pas rare de réaliser une migration en dumpant la base de données et en rechargeant les données dans le nouveau schéma après un traitement dédié des données.
Interaction entre applicatif et SGBDR
Dans de nombreux Systèmes d’informations, les SGBD(r) sont le nœud central qui permet à l’applicatif (aux logiciels métiers, aux SI) de se connecter et de synchroniser entre eux. Il est donc important pour un SGBD de fournir de nombreux connecteurs entre le SGBD et les langages utilisés. La plupart du temps, ces connecteurs simplifient une partie du travail, notamment en fournissant des constructeurs de requêtes à paramètres permettant d’éviter les attaques par injection SQL et augmentant la robustesse du code applicatif de manière générale.
Dans les langages de programmation orientés objet, il est souvent intéressant de fournir une vue objet des informations présents dans la base de données afin de simplifier l’interaction avec la base de donnée. Pour ce faire, on utilise des ORM qui réalisent une partie du travail automatiquement.
Ces ORM simplifient grandement le travail d’interaction avec l’applicatif, mais au détriment de problèmes de performance (multiplication de requêtes) et de la complexité de l’applicatif avec une couche d’abstraction supplémentaire.
L’interaction entre le modèle relationnel et un applicatif orienté objet est difficile et source de nombreux problèmes connus sous le nom d’ Object–relational impedance mismatch.
Les limites de performances des SGBDR
Pour un SGBDr comme PostgreSQL, l’utilisation normale est sur un serveur avec un ou plusieurs disques disponibles et un schéma pouvant tirer parti de la rapidité d’accès de certains disques par rapport à d’autres.
Cette structure est très efficace jusqu’à une quantité de données et de requêtes qui saturent les bus de communication entre les processeurs, la RAM et les disques durs.
La distribution des SGBD: Extensibilité (ou Scalabilité) horizontale
Pour un système de gestion de données, l’extensibilité horizontale consiste en des mécanismes permettant de distribuer le système sur plusieurs machines. On contourne ainsi les limites des bus de communications entre les processeurs et la RAM/les disques.
Il existe de nombreuses variations autour de ce qui peut être distribué dans un tel système:
- Distribution de la charge de travail (plusieurs copies activent de la même base de données). Typiquement, une distribution Primary/Replica avec une instance (Primary) en écriture/lecture et des instances (Replica) en copie en lecture seule.
- Distribution des données (les données sont réparties sur plusieurs machines). Par exemple en divisant une base de données en plusieurs morceaux via une clef de distribution pertinente. Typiquement, distribuer les données géographiquement.
Pour un SGBDr, l’objectif principal est de respecter autant que possible les propriétés d’ACIDité. Si la distribution Primary/Replica permet de garder ces propriétés, ça n’est pas compatible avec les situations où il y a de très nombreuses écritures concurrentes (mais efficace dans les cas où les écritures sont rares et les lectures très fréquentes.
Afin de garantir des propriétés d’ACIDité, il est possible de configurer un cluster de serveurs PostgrSQL pour que les transactions soient validées uniquement quand elles ont atteint les réplicats.
Exercice
Proposer des exemples de situations où une distribution de type Primary/Replica est efficace et des exemples où elle est à éviter.
Extensibilité horizontale et Sharding
Lorsqu’un système est distribué en données, s’il y a \(n\) serveurs et que les données sont partitionnées en exactement \(n\) morceaux, alors une panne réseau entre deux serveurs va empêcher l’accès à une partie des données. Ces pannes sont fréquentes et doivent être prises en compte.
Pour éviter ce genre de panne, il y a plusieurs stratégies :
- Faire en sorte que chaque serveur soit un serveur Primaire et possède une ou plusieurs répliques. En cas de panne, ces derniers peuvent prendre le relai pour répondre à la requête.
- Décomposer les données en morceaux qui se recoupent. Chaque donnée sera présente sur plusieurs serveurs simultanément.
En fait, le premier cas est un cas particulier du second qui est coûteux en serveur. Dans les deux cas, on appelle les morceaux de données des éclats (ou plus couramment des shards en anglais).
Pour qu’un système de données puisse passer à l’échelle, il faut nécessaire prévoir une architecture et une politique de distribution par éclats entre plusieurs nœuds qui le constitue. Malheureusement, en faisant cela on perd obligatoirement certaines garanties sur le fonctionnement de la base de données. Ceci est résumé par le Théorème CAP.
Le théorème CAP pour les systèmes distribués
Les explications et les illustrations viennent du poste de blog de Michael Whittaker.
On suppose qu’il est nécessaire de partitionner les données en plusieurs éclats présents sur plusieurs serveurs.
Les SGBD sont conçus pour apporter des garanties sur leur fonctionnement, y compris lorsque des pannes arrivent. Ainsi, les propriétés ACID permettent la garantie qu’un SGBDr qui donne une réponse de validation d’une requête l’a forcément prise en compte et a laissé le système dans un état valide. Si le système a une panne, alors il n’y aura de pertes de données que dans les cas extrêmes (système sans mécanismes de répliques avec le disque dur détruit par exemple).
Les SGBD distribués doivent également prendre en compte la possibilité que des pannes arrivent. Au contraire des systèmes classiques, les pannes sont fréquentes (pas forcément des nœuds de calcul, mais de leur interconnexion).
Dans l’absolu, les garanties recherchées sont :
- la cohérence de la base
- la disponibilité de la base
Nous allons voir que malheureusement, ces deux garanties ne peuvent être satisfaites simultanément pour un SGBD distribué.
Il s’agit du Théorème CAP.
Pour illustrer ce théorème, on va prendre un cas simple : deux nœuds \(G_1\) et \(G_2\) partagent une variable \(x\) qui a une valeur \(v_0\). On suppose que des clients peuvent se connecter pour écrire et lire cette variable pour chacun des deux nœuds.

Cohérence
On suppose qu’un client modifie la variable en envoyant une requête au nœud \(G_1\). Ce dernier accepte la modification et le signale au client. Pour que la base soit cohérente, il faut que si on requête la valeur \(x\) à \(G_1\) ou \(G_2\), cette valeur soit identique.
- Illustration d’un enchainement incohérent
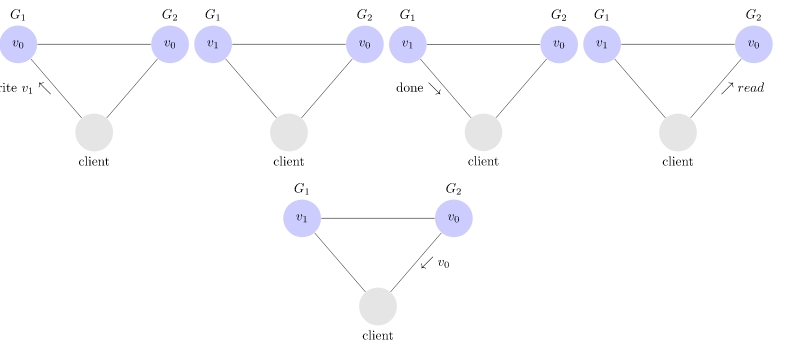
- Illustration d’un enchainement cohérent:
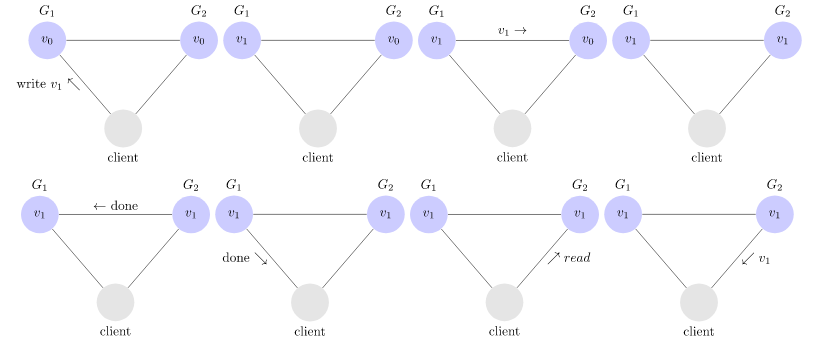
Pour que le système soit cohérent, il faut donc que \(G_1\) communique avec \(G_2\) pour mettre à jour la valeur sur tout le système avant de répondre au client que sa valeur a été acceptée.
Disponibilité
La disponibilité quant à elle est la contrainte que chaque requête doit recevoir une réponse.
La preuve du théorème
Si on suppose que la connexion entre \(G_1\) et \(G_2\) est interrompue et qu’un client souhaite mettre à jour la valeur. On a alors deux possibilités :
Si le système est cohérent, il ne peut valider la mise à jour et n’est donc pas disponible. Si le système valide la mise à jour et qu’une requête arrive sur \(G_2\), alors le système n’est pas cohérent.
Résumé du premier cours
- Les SGDBR sont les Systèmes de gestion de bases de données standards. Ils sont adaptés à de très nombreuses situations et performants.
- Leur efficacité en tant que système est formalisée au travers de leur respect (plus ou moins strict) des propriétés dites ACID.
- Quatre contreparties notables à cette efficacité :
- La difficulté de faire communiquer un SGBDR avec un langage orienté object (Object Relational Impendance mismatch)
- La difficulté de faire évoluer un schéma relationnel
- Une interaction avec l’applicatif compliquée
- La difficulté de rendre le système extensible aux très fortes charges, notamment en écriture.
- La distribution c’est compliqué: Le Théorème CAP.
Remerciement
Aux correcteurs anonymes.
Compiled the: dim. 07 janv. 2024 23:19:18 CET